This is the story of a project I started (almost exactly) two months ago. Not much of it is about the code itself (links at the bottom), but you can read what I did and why and stuff. I got to write a bunch of stuff in my favorite language and learn a new language along the way. I also got a little bit of control over my media.
GoPro Plus

I got a new GoPro Hero 8 for a trip I took recently. There were lots of exciting things to look at. The picture to the left was taken on January 20 at a resort in Siquijor.
The resort had quite good connectivity, and since I bought a new GoPro, I figured I’d try out the GoPro Plus 30 day trial thing they were offering. I could plug in my camera and my video and pictures and stuff would magicaly be stored safely in The Cloud™.
GoPros
GoPro Plus ends up being something like $5/mo (or I think $50/year if you do it annually). For this, you get unlimited storage and up to two camera replacements per year. It’s a pretty good deal to not have to worry about asset tracking, etc… And the camera replacement is a good incentive to actually try to use the thing.
The mobile app lets you browse around in the cloud-stored data and find things of interest to assemble into videos locally. It does a pretty good job of thinking up the edits and stuff for you.
Also, this isn’t my first GoPro, but you can upload video through their web UI. I uploaded a bunch of my old clips so I could store all my footage in one cloudy place.
Except, there were a few things that annoyed me about this.
GoCons
There were a few things that annoyed me about GoPro Plus early on (in no particular order):
- The web site made it quite difficult to navigate anything but your most recent media.
- While you could upload media and the camera could upload time lapse photos as a single medium, the web UI didn’t let you do this.
- Sometimes, things would just not upload and I couldn’t figure out why.
- Downloading in bulk (e.g., a day’s worth of stuff) is nearly impossible.
- Sharing is painful and broken.
As I became more of a power user, I found weirder, more obscure bugs (e.g., items stuck on their end in a particular state, or incorrectly recognized media).
But perhaps the biggest problem of all: I wanted to be able to make sure I could tell what media I’d uploaded and retrieve it all at will. I don’t know if this service will last forever, but I do know I would like my media to, so if they decide to shut down or something, I want to know I can get all my media out quickly and easily.
This is a fairly big flaw, as GoPro Plus doesn’t have an API. Well, officially…
Getting My Data

I finally decided to dive in on February 26. I found a little bit of stuff online where people had managed to get a listing from the media service, but these were all quite incomplete and didn’t meet any of my goals.
My goto language these days is Haskell as it’s consistently the easiest language I work in so I started exploring the API endpoint in ghci with wreq and aeson. As it turns out, their web app is just a javascript interface to the same API the mobile devices use, so it was relatively easy to just watch what it does and do the same thing.
I spent a bit of time over the weekend just making essential bits.
The first thing I figured I should do was capture all metadata from
the search results into a local sqlite database, along with the
thumbnails I could get from their image servers. I built my gopro
commandline tool to manage authentication tokens (and refreshes) and
then built a little web service that could give me my data back.
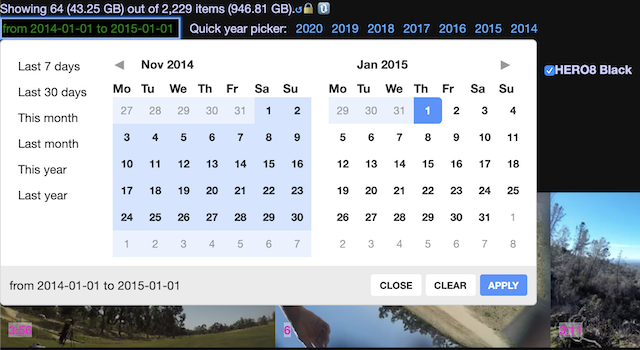
The GoPro Plus media-browser web site has endless scrolling of a few tens of items at a time. If I want to find the oldest of my 2,229 items I currently have stored, it might take me ten minutes just to scroll to the bottom (go to bottom of page, wait for load, repeat). Just getting to footage from the above trip is an excursion in itself.
Initially, I built an interface using crossfilter to let me do multi-dimensional filtering of my data quickly and easily, but I don’t much like working in JavaScript, so I decided to learn elm as part of this project. My new UI in elm was much more pleasant to work with, but there’s no crossfilter and javascript FFI is awkward even when you’re not trying to do something that fancy. But all I really needed was a collection of filter functions to apply in succession, so writing my own functional equivalent of crossfilter in elm ended up being basically something like this:
List.filter (\m -> List.all (\f -> f model m) allFilters) media
Given that I know when all of the media was captured and from what device, and what the type of media it was, I could easily build myself a date-based filter and camera filter and type filter and suddenly could ~instantly.
Need More Data
However, the GoPro Hero 8 captures some really rich telemetry. They open-sourced a parser for this which is super cool, but I ran into two problems with it:
- Their code seems very difficult to use (see the hundreds of lines of their basic demo).
- The demo didn’t even display very relevant data for most of my media.
That was a little unfortunate. I want access to all of the metadata, but after playing with their C code for a bit, I finally realized that’s quite an uphill battle.
So I finally just read their spec and wrote a gpmf parser from scratch. My core GPMF parser is under 100 lines of code and gave me complete data from every sample I ran into. The low-level data is a bit too low-level, so I added another ~176 SLOC to cover higher level concepts like GPS location and speed, face detection, etc…
Now I just needed to extract all the metadata from my ~700GB library.
However, you don’t need the entire content for this. It turns out
that as part of processing your video uploads, GoPro Plus produces a
few different variants of your content. This typically includes a
remarkably small one called mp4_low which usually carries the full
metadata. There are lots of qualifiers in there because things aren’t
entirely consistent, but it’s good enough:
ms <- asum [
fv "mp4_low" (fn "low"),
fv "high_res_proxy_mp4" (fn "high"),
fv "source" (fn "src"),
pure Nothing]
fv here is a function that locally caches a stream from GoPro by
name and then attempts to extract a GPMF stream from it. Often,
mp4_low has it and we’re done quickly and easily. If not, try the
higher res variant used for streaming in the browser, then the source,
then give up and declare there’s no GPMF (e.g., my old Hero 4 footage
doesn’t have any).
I added geographical areas to my database, a web handler to retreive
them, summarized location in my metadata and added a bit of
point-in-box Elm code. At this point, “Show me all of my media taken
in the Philippines in the year 2020” is two clicks, roughly instant,
and I see Showing 426 (49.88 GB) out of 2,229 items (946.81 GB)
along with all the nicely grouped thumbnails in my web UI.
Syncing

Syncing is relatively straightforward. I run my commandline tool periodically. It asks for paginated media ordered by upload date (descending) and keeps asking for pages until it sees a media ID it already has. Subtract the existing data and I can pull down whatever’s leftover.
I keep metadata, thumbnails, and downloadable variant metadata (minus URLs as they expire) in my media table. So grab these things for each missing record in concurrent batches (as not to do everything at once) and commit them to my local DB.
I have this retrieve function that, given a medium ID returns the
list of downloadable artifacts. The URLs themselves are signed s3
URLs that expire after a bit, so they’re only really interesting when
you’re actualy downloading an artifact. There are a few different
types of artifacts, some of which have one URL and some have
multiple. The resulting JSON includes url as a key for when there’s
one URL, and urls when there’s more than one. This sort of makes
sense, but it causes a lack of uniformity. Each one also has a
head/heads variation of the URL for issuing a HEAD request
instead of a GET request.
This detail sounds boring, but one interesting thing here a fun aeson-lens tip. If you have an arbitrarily complex chunk of JSON without much uniformity, but for any object anywhere within the structure, you want to remove a couple of keys, you could write something like this:
fetchSansURLs :: (HasGoProAuth m, MonadIO m) => MediumID -> m (Maybe Value)
fetchSansURLs = fmap (_Just . deep values . _Object %~ sans "url" . sans "head") . retrieve
(the actual version excludes urls and heads, but that’s not an
important detail and this line’s long enough).
Web Syncing
One seemingly unnecessary annoyance is that I had to reload my web page every time I did a commandline sync. I made this slightly better by just making a data sync (soft reload) button, but I thought it might be better to sync from the web UI itself.
The biggest problem with this was knowing what’s going on while this
is happening. I’m using an elm library called
toasty to put
little ephemeral popups on the screen. I’m also using MondaLogger
in the commandline tool. Combining these seems like a good idea.
Initially, I was asking the UI to poll the server to look for items in the database that should be displayed on the UI. This was gross for lots of reasons. I decided this might be a good time to learn a bit about websockets.
I’d “used” websockets once in the past when I added websocket support for my mqtt library, but this was mostly theoretical and all client-side. I figured server-side websockets in Haskell would be a bit of a challenge and client-side in Elm would be easy. My expectations were totally backwards.
I wrote a custom stderr logging function and a logging function that writes to an STM broadcast TChan. The latter is what I ended up using for websockets. I initially would do something fancy during the sync to redirect the log using a local logger mutation, but I figured I might as well just always log to the websocket channel in case any browsers are attached. It’s slightly less code.
My logger looks like this:
notificationLogger :: TChan Notification
-> (Loc -> LogSource -> LogLevel -> LogStr -> IO ())
notificationLogger ch _ _ lvl str = case lvl of
LevelDebug -> pure ()
LevelInfo -> note NotificationInfo
_ -> note NotificationError
where note t = atomically $ writeTChan ch (Notification t "GoPro" lstr)
lstr = TE.decodeUtf8 $ fromLogStr str
…and that’s hooked up to the web like this:
wsapp :: Env -> WS.ServerApp
wsapp Env{noteChan} pending = do
ch <- atomically $ dupTChan noteChan
conn <- WS.acceptRequest pending
WS.withPingThread conn 30 (pure ()) $
forever (WS.sendTextData conn . J.encode =<< (atomically . readTChan) ch)
At this point, my entire web-based sync on the server-side looks like this:
post "/api/sync" do
_ <- lift . async $ do
runFullSync
sendNotification (Notification NotificationReload "" "")
status noContent204
The NotificationReload that gets sent is a special message that
isn’t displayed by the browser, but just indicates that it should
reload the media catalog.
So, now that that’s done, let’s do the elm side. I won’t dump all
that code out here (it was a lot). The short story is that Elm
doesn’t have native websockets support and wiring it up was a bit of a
pain. It’s not too bad after that, though. Notification messages
come in and are dispatched easily enough:
doNotifications : Model -> List Notification -> ( Model, Cmd Msg )
doNotifications model =
let reload_ (m, a) =
(m, Cmd.batch [a, reload])
doNote n m =
case n.typ of
NotificationInfo -> toastSuccess n.title n.msg m
NotificationError -> toastError n.title n.msg m
NotificationReload -> reload_ m
NotificationUnknown -> toastError "Unhandled Notification" (n.msg) m
in
List.foldr doNote (model, Cmd.none)
Uploading

The upload process is complicated. I’ve not documented the whole in English, but my GoPro.Plus.Upload module does all of the things I’ve figured out how to do.
It’s quite facinating. A single medium upload can consist of multiple files (e.g., a timelapse photo series, or a video that was so large it broke into multiple files on its own). Additionally, they’re leveraging S3 chunked uploads such that when you define an upload and specify your chunk size (I’m using 6MB which is what they use in the web app), they give you a collection of pre-signed URLs to do the upload. The order you process these things doesn’t matter.
In the end, this means you can get massive parallelism for most uploads. Some of my uploads have consisted of hundreds of parts. I don’t have great connectivity where I am currently, but I can rsync my media to a location with good connectivity without any care for how long it takes. Once it arrives, I can use my commandline tool to upload with all the cores and network I can throw at the problem and then tie it up in the end.
I end up doing a lot of fun parallelism in this project, which often gets too large. I get a lot of use out of this function:
mapConcurrentlyLimited :: (MonadMask m, MonadUnliftIO m, Traversable f)
=> Int
-> (a -> m b)
-> f a
-> m (f b)
mapConcurrentlyLimited n f l = liftIO (newQSem n) >>= \q -> mapConcurrently (b q) l
where b q x = bracket_ (liftIO (waitQSem q)) (liftIO (signalQSem q)) (f x)
My commandline tool has two different upload commands because in one case you want to just blast a bunch of photos and clips up and in the other case, you want to sequence a series of parts into a single item of a specific type. This was a huge win for me because before I figured out how to do this, I had a couple folders of hundreds photos each that were GoPro time lapses that I couldn’t upload to GoPro using any of their tools.
Actually, it’s got a third upload command because I was able to recover a failed upload, but that was a super complicated process and their API doesn’t quite let you do this in a usefully automatable way.
Up…dating?
One issue I found in my bulk uploads is that I had a large number of items for which GoPro couldn’t recognize the camera. This was especially weird because I could. More specifically, in many cases, my own GPMF parser correctly identified the camera used, but GoPro didn’t know what it was.
I had found a URL from which I could GET the details of a medium by
its ID and I had observed in the process that it would mutate its
state by using a simple PUT. Can I do that?
I wrote a fixup command that lets me do bulk edits on the GoPro
side using SQL queries. e.g., consider the following query:
select m.media_id, g.camera_model
from media m join meta g on (m.media_id = g.media_id)
where m.camera_model is null
and g.camera_model is not null
This query emits one row per record where I know the camera type from
my metadata extraction, but GoPro does not. The
fixup
code will run that query, look up each item based on the returned
column media_id and update the JSON fields corresponding to the
column names returned from the SQL query (e.g., camera_model above)
and row values/types. I fixed up something like 800 bad items with a
single, simple command.
gopro fixup "select m.media_id, g.camera_model ..."
I also used this for individual edits since I could craft literal rows for edits easily enough and didn’t otherwise need to make a special tool. Not all fields are editable, though.
Extraction

But what if I want to move everything out of GoPro Plus right now?
I have a gopro backup command that does that. It uses local
credentials and my previously mentioned retrieve command to request
all the (signed) media URLs from GoPro Plus and then pushes them into
an SQS queue which delivers to an AWS
Lambda function whose job is to copy
the data into my own S3 bucket. Since GoPro itself stores all of its
data in S3, I figured moving the data from their bucket to mine using
AWS technologies made sense.
I did write some javascript for the lambda function, but it’s small and boring.
In my current, low-bandwidth, unreliable network state, I can move
~1TB of media out of GoPro cloud into bits I control with a small
command that takes a couple minutes to run. Most of the time on my
end is just making a couple thousand calls (though I’m using
mapConcurrentlyLimited here, of course). Then it’s just however
fast AWS Lambda wants to feed my function.
There’s really no reason I couldn’t just convert this to my own GoPro Plus from here. I’ve got browsing, media persistence, etc… I just need to do a bit of scaling, but I’m already using ffmpeg…
Resources / Current Status
Relevant github repos:
The GoPro Plus client API is fairly complete. There are parts I
understand, but haven’t really used because I haven’t figured out what
I want to do with them. e.g., I couldn’t figure out how to retrieve
the contents of a GoPro Plus collection (for sharing), so they’re not
super useful to me if they’re write-only. Also, device lists and
stuff aren’t that interesting, but this code is pretty easy to work
on. I’ve considered fixup-style editing into this library because
it’d be relatively easy.
The GPMF Parser low-level bits seemed to work with every sample I
could find, but I do think there are some theoretical things I didn’t
implement. I can’t find anything that uses them, though. The DEVC
stuff for higher-level abstraction has plenty of room for expansion in
areas that aren’t that interesting to my current project.
The GoPro CLI and Web UI are good enough for me right now, which isn’t saying that much since I’m not much of a web designer.
In Summary
With a bit of reverse engineering, learning a new programming language, delving into parsing video telemetry extracting poring through a silly number of third-party libraries to do all the things I want (e.g., exif, websockets, amazonka, etc…), I made a cloud service personally useful.
Hopefully someone else finds this work useful, too, but if I’m the only GoPro Plus user out there, then at least I’ve got awesome tools. :)


