What I’ve been Up To - A Virtual Blog Digest
I’ve been busy doing lots and lots of things. Much of it is work related, but I figured I’d quickly dump out a semi-structured list of things I’ve been doing since my last post (over three months!)
Many of these things deserve their own blog posts, but since I’ve clearly not been doing that, this digest will at least provide pointers for those interested.
mccouch
My primary job is to build a better couchbase server. mccouch is a key part of that by providing a memcached binary protocol interface to CouchDB. Bypassing HTTP and using memcached multi-set semantics gets us really good throughput for putting data on disk.
house temperature readers
My thermometers live on a 1-wire bus I wrote a stack and collector for that sends multicast data around the LAN I pick up from various things like the app that generates the image to your right.
I wanted to get that data stored into CouchDB, so I wrote a quick multicast temperature -> couchdb thing in coffeescript for node.js.
There were a couple of aspects of that I didn’t like (I think the primary thing was the VSS on the Linux box I had it deployed), so I ended up rewriting it in go. That’s been serving me pretty well.
couchdb duplicator
In early testing of replicator DB of CouchDB (i.e. playing with it around the house), I wrote a quick tool to have one CouchDB be a full mirror of another for all existing databases. I’ve got a few big databases. That was fun.
complex data-driven couchdb partial replication
I thought it might be fun to replicate my temperature database (~11M docs at the time) to another database filtered down to only the documents that met certain criteria specified by the replication request. That worked via a replication document specification, but backfilling wasn’t as fast as I’d like. I’ll need to do more work here.
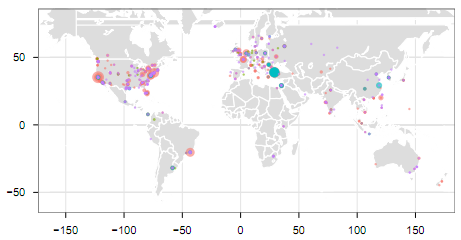
location project

I created my location project as a repository of location data from google latitude and tripit. It automatically populates itself with data from these sources and will let me explore my many travels interactively thanks to geocouch (my first time using it) and google maps.
As you can see, my many travels are typically to Tahoe and home.
code review

I did some work here and there on our gerrit dashboard thing that shows what we’ve been working on.
One somewhat notable thing was switching from gravatar to libravatar for the avatars. Most people probably didn’t notice, but libravatar is pretty cool, and it’s got pass-through compatability.
I’ve got one of these for android as well, though kernel.org’s outage has made it pretty stale.
photo app work
I did a bunch of work on my photo couchapp. I use this to store and replicate all of my photos. It’s probably not exciting to most people (though everyone’s free to use it for a great way to use the cloud to benefit without dataloss or availability risk).
I made a bulk edit screen and built myself a proxy for accessing the full-size image I have mirrored onto S3 via a signing proxy redirector thing to my house. This is a service I wrote in (I think) python. I originally tried to write it in node.js, but I found a bug in the S3 API I was trying to use and just wanted it to work.
readme
I wrote this web app for our support guys to track discussions of interest from around the web. Instead of them having to have duplicate RSS reader config, lots of mail setups and stuff, they just have one screen they can look at and share and track state of all the things they need to respond to.
(and sorry, the app doesn’t have a README, if anyone’s interested, I can start documenting it)
reddit pics
Another tiny app I wrote just for me, my reddit pics app presents me with a stream of images from reddit and lets me mark the ones I want to keep, while deleting the rest.
(well, deleting in this case means removing from my local DB which is a replicate of an upstream master DB that keeps All The Things)
gomemcached update
Someone filed a bug report against my go memcached server that involved little more than an update for a newer compiler, but that was fun to play with again.
gotap
I don’t even remember why, but I wrote an implementation of the memcached tap protocol in go. This is the protocol upon which we build replication, failover, ETL, etc… in membase.
html5 page idle stuff
HTML5 added a feature that allows you to detect when the browser renders your page hidden (most commonly by switching tabs). This is really awesome for things like my code review and reddit apps since I can disable the realtime data stream to pages that aren’t even being looked at (and enable it when someone looks again!)
web de-auth proxy
I did some private use map visualizations use google maps (which Volker Mische ported to the jquery openmap API). Unfortunately, they also used private databases and running a web screen saver or full-time web browser that requires auth can be a minor annoyance.
That sounded like a great job for node.js, so I wrote a quick deauthing proxy in node.js using the built-in http server, client, and a pipe. It was a bit more complicated than I initially assumed it would be, but that was basically it.
Unfortunately, it was very unreliable. Not sure if my bug, or node.js, but after a few minutes, it’d stop answering any HTTP requests, or even acknowledging that it received one. That kind of sucked.
So I wrote a new one in go. It’s the same number of lines (once I added commandline parsing and stuff), but has worked flawlessly since I deployed it even with a bunch of concurrent clients grabbing lots of data and long-polling and what-not.
fprof visualization

Part of our ongoing effort of performancing everything involves understanding everything. I did a little bit of stuff with a tiny module or two showing me the current state of things, but that really didn’t help understanding things moving forward.
My first pass at this was to understand the data produced by Erlang’s fprof and organize it into a giant document we can pan and trace and see where things are unnecessarily hot and why. I wrote my fprof dot thing to do that work. It’s not quite productionalized, but it’s worked well for me.
web pipe
Turns out, graphviz from homebrew is broken on Lion (one of the relatively few issues I’ve run into), and I wanted to be able to look at stuff I was building, so I made a little web pipe tool that let me have processes that run on remote machines take data from stdin and pass it back to stdout on my local machine using curl and node.js. That worked pretty well.
erlang dtrace
This definitely deserves a post by itself, but in the meantime, I’ve been working to add proper dtrace support to erlang (once and for all!)
I mentioned my first attempt with fprof above. There was a second attempt at digging out enough information where I used the low-level tracing facilities of erlang itself to really understand where everything was happening. It will really tell you a lot, but you have to write a lot of tools and really just end up doing it yourself.
So then came dtrace.
Anyone who knows dtrace will understand this, and anyone who knows me will have heard it all (all!) before, but dtrace answers all the questions. Life, the universe, everything.
A co-worker asked me how long it takes for a message sent from one erlang process to be picked up in another process. Without as much as picking up an editor, I blasted out this commandline and was able to say it’s around 8µs ± a few nanoseconds for clock skew across cores and processes that are scheduled independently on other threads regardless of my message having been sent.
My DTrace wiki page is a starting point for getting the stuff going and knowing where all the probes are (basically function/bif/nif entry/return, process scheduler events, gc events, allocation events, message sending, hibernate, probably more).
It makes it really easy to test things that are just invisible to
erlang itself – like knowing which erlang functions cause heap growth
that directly causes the OS itself to actually mmap/sbrk in more
memory since it all correlates.
You, too, can know it all.
lua (again)
Way back in October of last year I started experimenting with server-side scripting in membase. I spent a bit of time a couple of weeks ago and actually got a pretty rich set of APIs and stuff built and was able to demo complex server-side manipulation and batch processing with a dynamically extensible client.
There were lots of fun challenges inside of this (e.g. multiple threads operating on lua concurrently while being able to define global functions available to all future sessions while blocking accidental global variable definition). I’m hoping to get it into some products as a way to enhance testing and more quickly extend client functionality (though ideally users won’t even know about it).
Glue code can be a lot of fun. I’ve really got a lot more to say about this one, too.
couchconf
I did a CouchConf talk on jQuery in San Francisco. There are a lot more coming, so I might be doing more of this on different topics very soon.
For this one, I did a bunch of prep work, thought about what I was going to do, etc… Then I threw it all away and finalized my presentation with prezi.
I wanted to demo some of the stuff I was talking about, so I thought of something new and literally wrote the app on the ride up to the show (and kept enhancing it until my talk).
The app itself isn’t that exciting – it shows realtime trades of bitcoin across all exchanges (data populated by a little go app that I threw together to replace a python one I didn’t like).
git tree hash based positive test result memoization
I can’t remember what I was doing, but it involved running a bunch of tests with git test sequence and they weren’t fast enough. Someone had given me some memoization code a while back, but it was commit based and used refs and I think it lacked a bit of perfection.
To speed up my testing on an evolving tree, I updated it to record successful test results by the test issued and the tree hash into the object store directly. This means there are dangling objects that will eventually be cleaned up, but this is going to happen around the time that you don’t care about those tests results anyway, so it’s perfect.
Everyone: abuse the git object store to make your lives better.
leveldb - first impressions
Somewhere along the way, I wrote a backend for membase that stores data in leveldb. It’s a lot of fun to work with, and as you can see in my results, it’s up to 10x faster than our highly tuned SQLite on inserts on SSD (less on EC2, but that’s OK). It’s certainly more consistent.
It’s not perfect, though. It’s not really any faster on fetches or commits (sometimes a lot slower) and I’ve got one crashing bug in leveldb, that I need to get out of the way before I can even show it to anyone.
the programming challenge
I got to review some code from a candidate a few times for a fairly simple “let me see your handwriting” kind of coding question we pass around.
The basic problem involves reading a file with a bunch (~1M) usernames into a structure in memory and providing a function to tell you whether a given user is in it.
Candidates invariably want to build something like a trie, but often fall into this trap where they believe pointers don’t take up space (even arrays of pointers, apparently). I wanted to give it a go, so I did a plain C implementation that ended up being fewer lines of code than what we’d got from our candidates, used about 10% of the memory and ran many times faster.
I sucked some other people’s time into this as well. If you’d like to offer a suggestion, here’s a tool that generates 100M usernames for you to try out. (finally got to use a bloom filter, yay! (and no, the answer doesn’t involve a bloom filter unless you want to do a times/space tradeoff thing)
If you want to try it, note that my program is < 100 lines of plain C (no external libraries) and uses 1.26GB of RAM on my macbook for 100,000,000 usernames. It loads and indexes them in 84 seconds and spends another 31 seconds verifying it can find each of the 100,000,000 users within that list (+ 4 more that are known to not be there). Please do better than that.
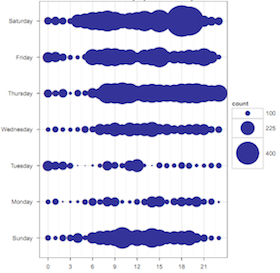
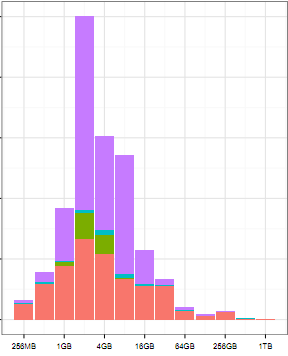
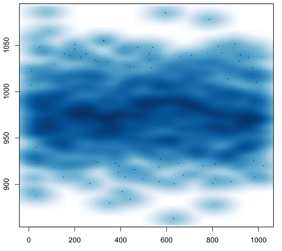
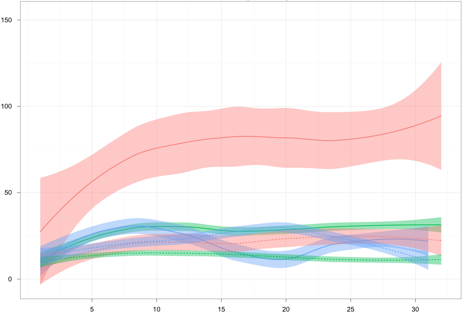
program like a pirate
I’ve written a couple thousand lines of R in the last month or so.
Here are some examples taken completely out of context. I also owe a blog post on how incredibly easy it is to just throw all your data into CouchDB and then look at it with R.
python heatmap
Some of my visualization work wasn’t just couchdb -> R to pdf or png or something, but I wanted to do some slightly different stuff.
As part of my upcoming pycodeconf talk on breakdancer, I wanted to come up with some visualization on what it looked like for a cluster of tests to fail out of a 130k test suite in a way that might be consumable by a human. For this, I grabbed a python heatmap implementation and hacked on it a bit to do what I wanted.
Well, that didn’t work for me all that well, but it did get me interested in doing an interactive heatmap animation of geographical density data changing over time, so I ended up doing that instead and updating the library a little bit to do it. That was more successful.
couchdb wikipedia
Over the weekend, I loaded all of wikipedia (2011-09-01) into a couchdb and added a geo index over all of the features I could find that reference a “place.” It’s pretty fun to look around and find articles by bounding box. It’s also pretty decently fast to see the r-tree go with a bit over 300,000 points across the world.
Hopefully, I’ll end up making an offline wikipedia at some point, but I’ve got a lot of projects lined up ahead of this.
…but mostly
It’s been customer and product work. I’ve got a variety of really interesting problems at customer sites (e.g. a 100 microsecond SLA for one, high volume realtime data analysis across many dimensions for another).
We’re continuing to define and build UnQL for everybody and attending and hosting lots of talks all over the place. I hope to see you at some of them.
(and if you program in C, C++, objective C, java, go, erlang, javascript, R, ruby, and/or python and want to help use and build some awesome technologies, I could use some help)


