For years, people have used memcached to scale large sites. Originally, there was a simple modulo selection hash algorithm that was used. It still is used quite a bit actually and it’s quite easy to understand (although, it’s shown regularly that some people don’t truly understand it when applied to their full system). The algorithm is basically this:
servers = ['server1:11211', 'server2:11211', 'server3:11211']
server_for_key(key) = servers[hash(key) % servers.length]That is, given a hash algorithm, you hash the key and map it to a position in the server list and contact that server for that key. This is really easy to understand, but leads to a few problems.
- Having some servers have greater capacity than others.
- Having cache misses skyrocket when a server dies.
- Brittle/confusing configuration (broken things can appear to work)
Ignoring weighting (which can basically be “solved” by adding the same server multiple times to the list), the largest problem you’ve got is what to do when a server dies, or you want to add a new one, or you even want to replace one.
In 2007, Richard Jones and crew over at last.fm created a new way to solve some of these problems called ketama. This was a library and method for “consistent hashing” – that is, a way to greatly lower the probability of hashing to a server that does not have the data you seek when the server list changes.
It’s an awesome system, but I’m not here to write about it, so I won’t get into the details. It still has a flaw that makes it unsuitable for projects like membase: it’s only probabilistically more likely to get you to the server with your data. Looking at it another way, it’s almost guaranteed to get you to the wrong server sometimes, just less frequently than the modulus method described above.
A New Hope
In early 2006, Anatoly Vorobey introduced some code to create something he referred to as “managed buckets.” This code lived there until late 2008. It was removed because it was never quite complete, not understood at all, and we had created a newer protocol that made it easier build such things.
We’ve been bringing that back, and I’m going to tell you why it exists and why you want it.
First, a quick summary of what we wanted to accompish:
- Never service a request on the wrong server.
- Allow scaling up and down at will.
- Servers refuse commands that they should not service, but
- Servers still do not know about each other.
- We can hand data sets from one server another atomically, but
- There are no temporal constraints.
- Consistency is guaranteed.
- Absolutely no network overhead is introduced in the normal case.
To expand a bit on the last point relative to other solutions we looked at, there are no proxies, location services, server-to-server knowledge, or any other magic things that require overhead. A vbucket aware request requires no more network operations to find the data than it does to perform the operation on the data (it’s not even a single byte larger).
There are other more minor goals such as “you should be able to add servers while under peak load,” but those just sort of fall out for free.
Introducing: The VBucket
A vbucket is conceptually a computed subset of all possible keys.
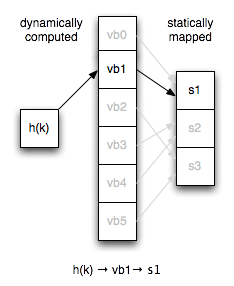
If you’ve ever implemented a hash table, you can think of it as a virtual hash table bucket that is the first level of hashing for all node lookups. Instead of mapping keys directly to servers, we map vbuckets to servers statically and have a consistent key → vbucket computation.
The number of vbuckets in a cluster remains constant regardless of
server topology. This means that key x always maps to the same
vbucket given the same hash.
Client configurations have to grow a bit for this concept. Instead of being a plain sequence of servers, the config now also has the explicit vbucket to server mapping.
In practice, we model the configuration as a server sequence, hash function, and vbucket map. Given three servers and six vbuckets (a very small number for illustration), an example of how this works in relation to the modulus code above would be as follows:
servers = ['server1:11211', 'server2:11211', 'server3:11211']
vbuckets = [0, 0, 1, 1, 2, 2]
server_for_key(key) = servers[vbuckets[hash(key) % vbuckets.length]]It should be obvious from reading that code how the introduction of vbuckets provides tremendous power and flexibility, but I’ll go on in case it’s not.
Terminology
Before we get into too many details, let’s look at the terminology that’s going to be used here.
- Cluster
- A collection of collaborating servers.
- Server
- An individual machine within a cluster.
- vbucket
- A subset of all possible keys.
Also, any given vbucket will be in one of the following states on any given server:

- Active
- This server is servicing all requests for this vbucket.
- Dead
- This server is not in any way responsible for this vbucket
- Replica
- No client requests are handled for this vbucket, but it can receive replication commands.
- Pending
- This server will block all requests for this vbucket.
Client Operations
Each request must include the vbucket id as computed by the hashing algorithm. We made use of the reserved fields in the binary protocol allowing for up to 65,536 vbuckets to be created (which is really quite a lot).
Since all that’s needed to consistently choose the right vbucket is for clients to agree on the hashing algorithm and number of vbuckets, it’s significantly harder to misconfigure a server such that you’re communicating with the wrong server for a given vbucket.
Additionally, with libvbucket we’ve made distributing configurations and distributing configuration, agreeing on mapping algorithms, and reacting to misconfigurations a problem that doesn’t have to be solved repeatedly. Work is under way to get ports of libvbucket to java and .net, and in the meantime moxi will perform all of the translations for you if you have a non-persistent clients or can’t wait for your favorite client to catch up.
One Active Server
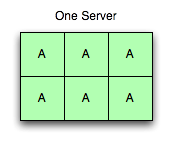
While deployments typically have 1,024 or 4,096 vbuckets, we’re going to continue with this model with six because it’s a lot easier to think about and draw pictures of.
In the image to the right, there is one server running with six active buckets. All requests with all possible vbuckets go to this server, and it answers for all of them.
One Active Server, One New Server
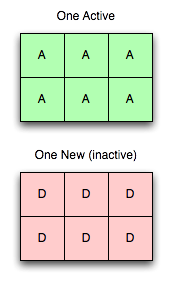
Now let us add a new server. Here’s the first bit of magic: Adding a server does not destabilize the tree (as seen on the right).
Adding a server to the cluster, and even pushing it out in the configuration to all of the clients, does not imply it will be used immediately. Mapping is a separate concept, and all vbuckets are still exclusively mapped to the old server.
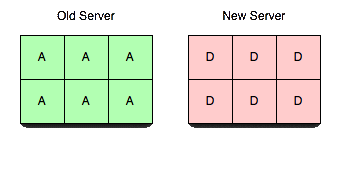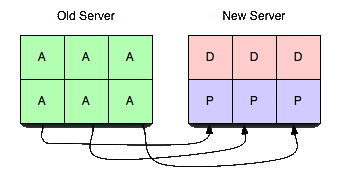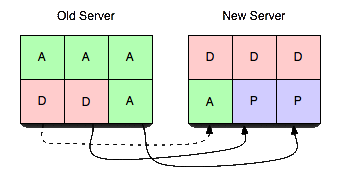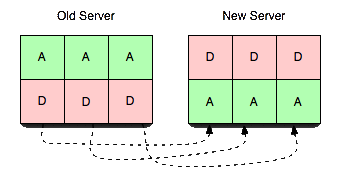
In order to make this server useful, we will transfer vbuckets from one server to another. To effect a transfer, you select a set of the vbuckets that you want the new server to own and set them all to the pending state on the receiving server. Then we begin pulling the data out and placing it in the new server.
By performing the steps in this exact order, are able to guarantee no more than one server is active for any given vbucket at any given point in time without any regard to actual chronology. That is, you can have hours of clock skew and vbucket transfers taking several minutes and never fail to be consistent. It’s also guaranteed that clients will never receive incorrect answers.
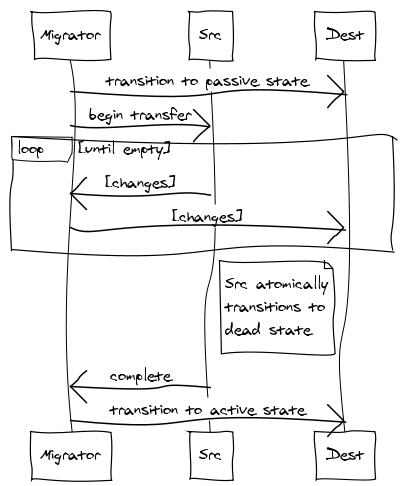
- The vbucket on the new server is placed in a pending state.
- A vbucket extract tap stream is started.
- The vbucket tap stream atomically sets the state to dead when the queue is in a sufficient drain state.
- The new server only transitions from pending to active after it’s received confirmation that the old server is no longer servicing requests.
Since subsections are being transferred indepenently, you no longer have to limit yourself to thinking of a server moving at a time, but a tiny fraction of a server moving at a time. This allows you to start slowly migrating traffic from busy servers at peak to less busy servers with minimal impact (with 4,096 vbuckets over 10 servers each with 10M keys, you’d be moving about 20k keys at a time with a vbucket transfer as you bring up your eleventh server).
You may notice that there is a time period where a vbucket has no
active server at all. This occurs at the very end of the transfer
mechanism and causes blocking to occur. In general, it should be rare
to observe a client actually blocked in the wild. This only happens
when a client gets an error from the old server indicating it’s done
prepping the transfer and can get to the new server before the new
server receives the last item. Then the new server only blocks the
client until that item is delivered and the vbucket can transition
from pending to active state.
Although the vbucket in the old server automatically goes into the
dead state when it gets far enough along, it does not delete data
automatically. That is explicitly done after confirmation that the
new node has gone active. If the destination node fails at any
point before we set it active, we can just abort the transfer and
leave the old server active (or set it back to active if we were
far enough along).
What’s This About Replica State?
HA comes up a lot, so we made sure to cover it. A replica vbucket
is similar to a dead vbucket in that from a normal client’s
perspective. That is, all requests are refused, but replication
commands are allowed. This is also similar to the pending state in
that records are stored, but contrasted in that clients do not block.
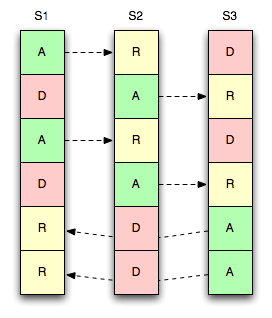
Consider the image to the right where we have three servers, six vbuckets, and a single replica per vbucket.
Like the masters, each replica is also statically mapped, so they can be moved around at any time.
In this example, we replicate the vbucket to the “next” server in the
list. i.e. an active vbucket on S1 replicates to a replica
bucket on S2 – same for S2 → S3 and
S3 → S1.
Multiple Replicas
We also enable strategies to have more than one copy of your data available on nodes.
The diagram below shows two strategies for three servers to have one active and two replicas of each bucket.
1:n Replication
The first strategy (1:n) refers to a master servicing multiple
slaves concurrently. The concept here is familiar to anyone who’s
dealt with data storage software that allows for multiple replicas.
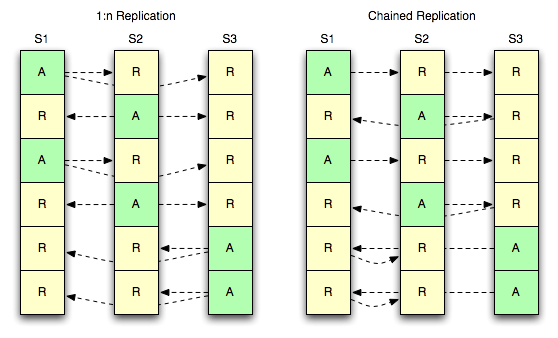
Chained Replication
The second strategy (chained) refers to a single master servicing
only a single slave, but having that slave have a further downstream
slave of its own. This offers the advantage of having a single stream
of mutation events coming out of a server, while still maintaining two
copies of all records. This has the disadvantage of compounding
replication latency as you traverse the chain.
Of course, with more than two additional copies, you could mix them
such that you do a single stream out of the master and then have the
second link of the chain V out a 1:n stream to two further servers.
It’s all in how you map things.
Acknowledgments
Thanks to Dormando for helping decipher the original “managed bucket” code, intent, and workflows, and Jayesh Jose and the other Zynga folks for independently discovering it and working through a lot of use cases.


