I got around to pushing out a new RC of spymemcached today. It’s been a while, but I’m glad I got around to it.
The announcement has the release notes (also in the tag), but there is a particular optimization I’ve been thinking about for a while, and would like to go over here somewhere below.
But first, I’ll frame it with a bit of memcached protocol fundamentals.
Introduction to Quiet Operations
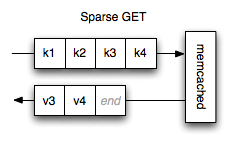
Back when we were initially designing the binary protocol, we were considering how we’d handle the multi-gets. We went through several proposals until we realized that the actual essense of multi-get model was really just a class of operation that allowed us to infer some of the responses.
The above diagram shows a simple case of a multi-get. We ask for the values behind four keys. The server sends us responses for two of those keys and then says it’s done. In a client, we can safely assume that it just didn’t have the other two. It doesn’t need to actually tell us that.
So in the binary protocol model, we just made a type of command that
didn’t respond with “uninteresting responses.” It’s easy to see how
in a get operation, the not found response is uninteresting as we
can infer it.
Other Quiet Operations
Shortly before the actual 1.4.0 release of memcached, we defined semantics for all “quiet” operations in such a way that allowed us to maximize efficiency without compromising correctness.
The binary protocol definition goes through these in tremendous detail, but those familiar with the Unix philosophy will probably find such things intuitive.
For example, in Unix, the rm command does not print out any output
on success. If it completes and didn’t say otherwise, you can assume
it was successful.
Similarly, a quiet delete operation doesn’t need to tell us that it
successfully deleted something. That’s its job. We want to know when
it fails to do it.
Optimizing with a Quiet Set
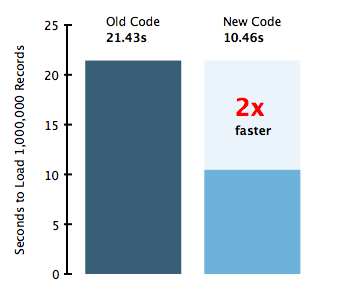
The optimization I was interested in was making a multi-set type operation that worked similarly to the multi-get functionality. After struggling with what such an API might look like, I finally decided that the right thing to do is not change the API at all.
Instead, I do something similar to multiget escalation – an optimization that’s been part of spymemcached for a long time now. If many threads are pushing sets in (or even a single-thread since the typical use-case of set is async), the packetization of these commands escalates a sequence of similar commands into a single sparse operation working on all of the items together.
While YMMV, my cache loader test ran consistently twice as fast.
Previously, one million requests would require the client to process one million responses. Now, one million requests (assume none fail) will require the client to process one tiny response.
If any do fail, the respective callers will, of course, be notified. The ones that don’t fail receive synthetic callbacks as the client infers their success.
What You Need to Do
If you’re using spymemcached, upgrade and you get the optimizations.
If you’re a client author, see how much better things are for your users as you make broader use of quiet operations of the binary protocol.


